📢 ANNOUCEMENT 1Legion to Deploy $50M in GPUs with Classover


August 12, 2025

At 1Legion, we’re always looking ahead — because the future of computing doesn’t wait. The launch of the NVIDIA RTX 5090 marks one of the most significant leaps in GPU technology since the arrival of the RTX 4090. And for AI, machine learning, and high-performance computing (HPC), the difference isn’t just about bigger numbers on a spec sheet — it’s about unlocking new possibilities.
When the RTX 4090 arrived, it set a new standard for AI workloads, large language model (LLM) inference, and high-resolution rendering. The RTX 5090 takes that foundation and pushes it even further, delivering:
In short: more speed, more headroom, and more efficiency — exactly what next-gen AI workloads demand.
Recent benchmarks show the RTX 5090 delivering up to 40% faster inference on popular LLMs compared to the 4090. For model training, that means fewer hours to converge; for real-time inference, it means lower latency and more simultaneous requests served.
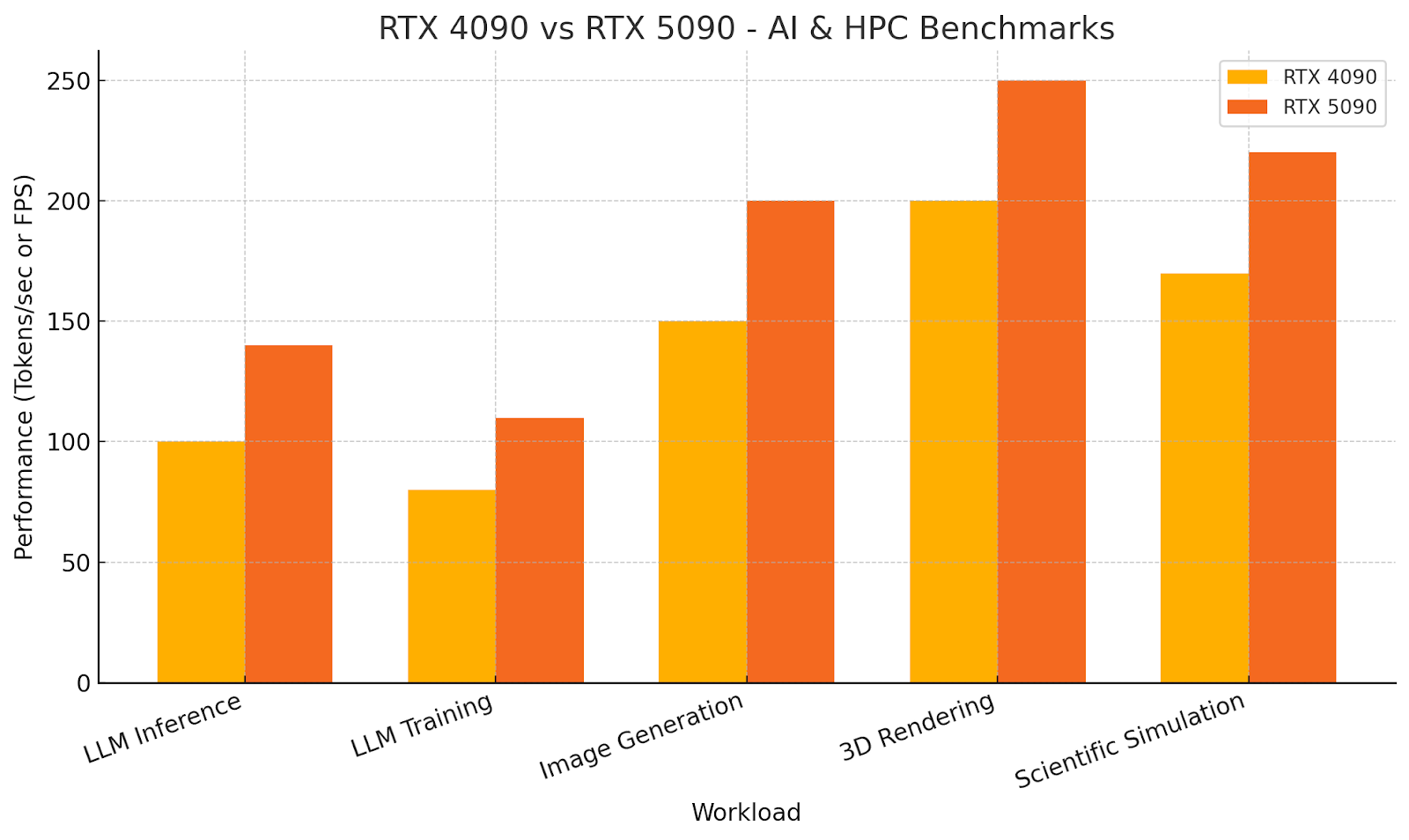
For example:
If your work involves LLM fine-tuning, multi-modal AI, or heavy-duty simulation, this difference translates directly into time saved — and more experiments run per week.
The RTX 4090 remains an incredible GPU and delivers strong value for many workloads. If your models fit comfortably within its VRAM limits and you’re not pushing extreme batch sizes, it’s still a powerful choice.
However, the RTX 5090 is built for those pushing boundaries:
For teams working at the edge of AI’s capabilities, the 5090’s additional performance is not just a luxury — it’s a competitive advantage.
You don’t need to invest in costly on-premise hardware to harness the 5090’s power. At 1Legion, we make it available on demand — so you can train, fine-tune, and deploy without the wait or upfront expense.
Whether you choose the RTX 4090 for balanced performance or the RTX 5090 for bleeding-edge speed, you’ll get:



